
前言
“可用性测试” ,还有一个名字叫 “用户测试”,但有些人反对使用 “用户测试” 这个名字,因为那听起来像是研究人员在测试用户本身。但实际上并没有测试用户本身,我们只是在与用户一同测试这个界面。
一、为什么要做可用性测试
难道一名优秀的设计师不知道怎样设计出一个好的用户界面吗?—— 事实上,即使是最优秀的设计师也不敢保证一步就设计出完美的界面。可用性测试帮助我们,以观察真实用户为基础,来进行设计迭代。根据研究内容的不同,不同的可用性测试有着不同的目标。
🔍 识别问题(Uncover Problems):新界面是否存在使用障碍
✨ 优化设计(Discover Opportunities):探索界面潜在的可优化项
👨🏻💻 理解用户(Learn About Users):理解用户的使用偏好和习惯
在设计的时候,通常会有不止一种解决思路,作为设计师,我们通常会在产品设计阶段提供好几种并行的设计方案。而每个用户对于界面的理解又是很不一样的,其间可以产生无数种组合方式。但设计师不可能为每个用户都单独设计,我们需要测试设计稿。
二、可用性测试的要素
可用性测试的类型有很多种,但往往都离不开以下三个核心要素:
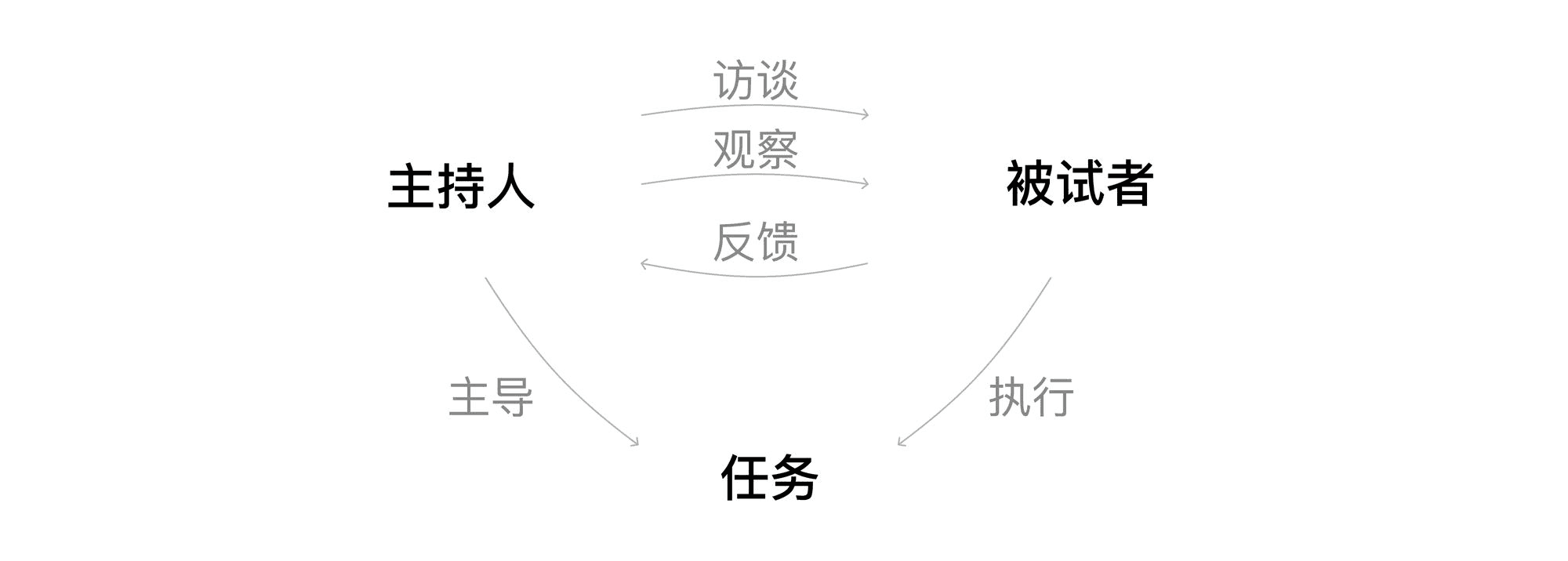
主持人(Facilitator):引导被试者完成整个测试任务,观察被试者的行为,倾听反馈,有时候也会主动问一些问题。
任务(Tasks):模拟真实场景中的真实任务
被试者(Participant):产品或服务的真实目标用户
2.1 要素一:主持人
💡 主持人引导被试者,给予指示和支持。
主持人让整场测试有个轻松的开始
在测试任务开始之前,我们可以提一些开放性的问题。比如询问被试者一些使用习惯,让被试者回忆曾经使用某产品/功能的操作偏好之类的,从而更好进入状态。
主持人引导被试有声思考
在测试过程中,通常需要被试者有声思考(Think Aloud)。但被试如果不知道我们有这样的要求,大多数情况下他们会静默操作,不会给你任何反馈。所以主持人可以在任务介绍前,可以加上一句:“接下来我会设定一些情景任务,您按照自己的使用习惯进行操作即可,您可以边操作边说,以便我们理解您的行为。”
主持人不干预
被试在测试的过程中,难免会发生一些不顺利的情况,主持人记录下这些意外场景,在单个测试任务结束之后追问被试者刚才操作时的感受,注意追问时不要带入主观想法。
接下来我们有一个简单的例子,说明主持人在测试过程中应该保持怎样的姿态:

上图的第一种问法试图在复述被试者遇到的场景。
但作为旁观者,这样的复述不一定反应了被试者的真实感受。如果被试者在某个地方迟迟不肯操作,在旁观者看来是用户不知所措,进而将这种现象定义为“困难”,但实际上有可能只是被试者的个人操作习惯。另外,“导航”、“组件”这样的术语是不应该在用户访谈中出现的,原因显而易见。
第二种问法更为激进,不仅提前定义了“困难”,还试图责备被试人员。 可用性测试的目的是发现问题,而不是解释。过度的解释可能让整个测试陷入尴尬,甚至争执。
第三种问法更值得推荐一些。 没有向被试暗示任何内容,而是等待被试说出自己的感受。

2.2 要素二:任务
💡 可用性测试中布置的任务,需要是真实用户在真实使用场景中会发生的任务。
这些任务可以是非常具体的,比如 “删除某一封邮件”;也可以是非常开放的,比如 “与你的朋友建立沟通,方式不限”。任务的设计取决于可用性测试的类型,以及本次测试要研究的问题。在产品进入设计阶段时,通常是以识别问题为主的“形成性”可用性测试,样本数量在8-10个之间。因此,设计的任务都比较具体,任务流程相对封闭。
以流程设计为测试重心的,可以布置开放的任务。

主持人:“假设你收到了好友A发来的邮件,现在需要你查收一下。您根据您的使用习惯进行操作就好,如果遇到任何问题可以向我们反馈。”
以某一界面为测试重心的,可以布置具体的任务。

主持人:“假设邮件1对你来说比较重要,你需要将其标记为红色,在这个界面上你会如何操作呢?“
2.2.1 设计任务的雷区
关于任务的设计,以下10条内容是应该尽可能避免的:

其中第1条和第2条,是指不要把任务设计得过于具体。
例1:用鼠标单击屏幕右上角的红色关闭按钮。 例2:关闭这个页面。
例1的任务设计不仅告诉了被试者去哪儿操作(屏幕右上角),还告诉被试如何操作(鼠标单击)。这相当于提前把答案写在考卷上,对于测试设计稿来说没有任何意义。
第6条和第7条,是指不要在任务设计中,有意渲染某种情绪,尤其是当这个界面涉及一些新功能展示时。
例3:来试试我们的新开发的消息回复功能吧! 例4:在这个页面上回复对方。
例3与例4相比就少了很多客观性,似乎在这句话中提前给被试者植入了一些期待,在任务的设计过程中是不应该出现的。
为了防止在实际测试过程中可能出现的问题,有时间的话最好可以进行一场内部预测试,来演练你准备的测试任务。
测试过程中除了主持人口头陈述任务之外,我们也可以把任务书直接给被试者。通常需要被试者在把每个任务读出来,确保被试者完整地阅读了指引。
2.3 要素三:被试者
💡 被试者应该是一个产品或者服务的真实用户。
或者至少,有相似产品的使用经历的竞品使用用户。最佳的策略是提前准备一个用户画像,简略的就行,交给负责招募的同事(可能是产品、运营、销售)。寻找被试者、安排测试时间等的工作相对繁琐,通常整个小队要经历以下几个步骤:
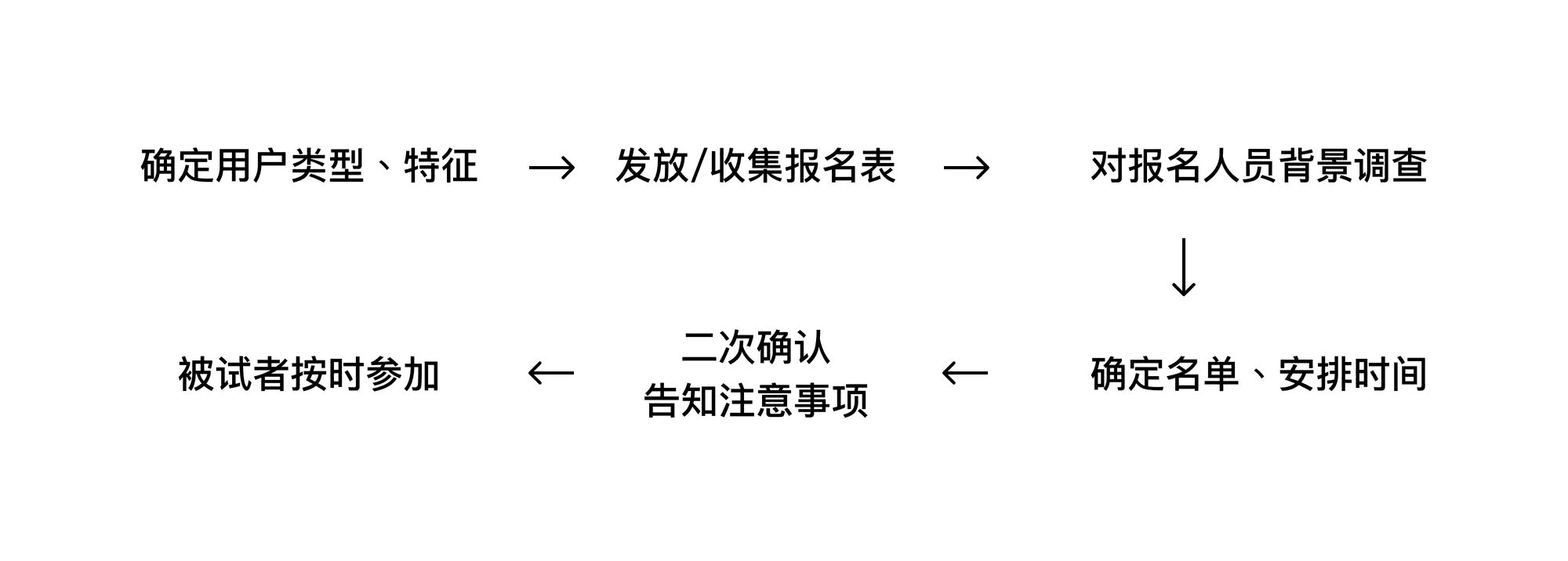
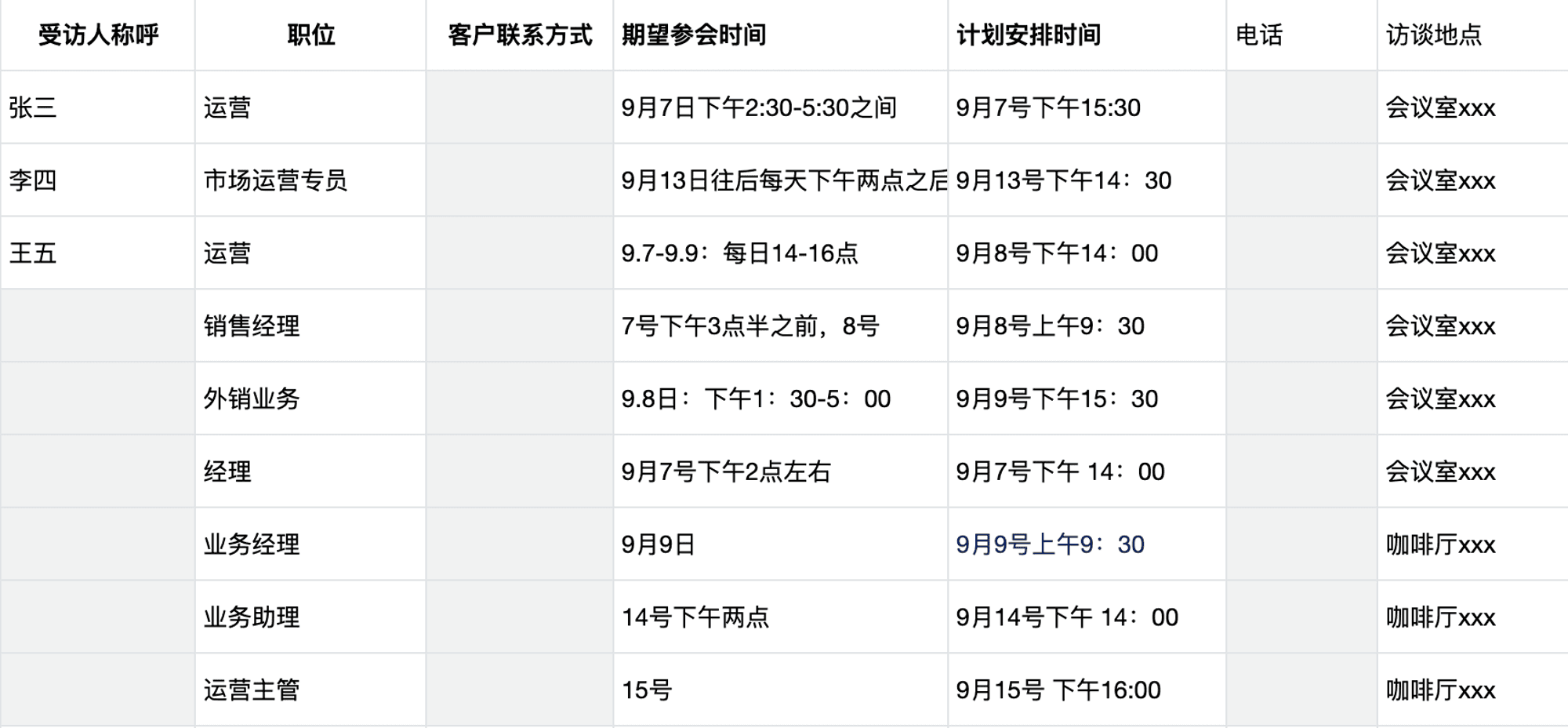
在确定好名单之后,我们使用一张在线表格记录了每位被试者的期望时间和计划安排时间。产品同事在会在测试开始的前一天邮件通知到被试者测试内容和注意事项。如果不确定邮件是否送达,可以提前向被试者电话确认。所以联系方式应在征得允许的情况下,收集2种以上。
三、可用性测试的产出
另外一个可用性测试的重点内容,是关于测试结果的分析。而在做结果的分析之前,研究人员需要对结果有预期。通过可用性测试可以得出的结果,可以大致分为两类,定性的、定量的:
可用性测试数据的类型(图片来源:作者自绘)
3.1 定性的可用性测试数据
定性的数据适用于直接评估设计的可用性。研究人员观察被试者在与指定界面交互的过程中,被试者是否感到阻塞或者不理解。进而识别哪些设计是有问题的,哪些设计是放心的。

通常,为了深入了解这些设计问题,研究人员还会进一步追问被试者的使用体验,感到阻塞的原因。其形式通常是文字记录📝。
所有测试结束后,通过收集到的数据,设计师来判断哪些地方确实设计得不好。
3.2 定量的可用性测试数据
定量的数据适用于间接评估特定设计的可用性。对于定量的可用性测试,在设计其任务时,需要给出一个定义好的标准答案,或者标准操作路径。并且,获取定量数据时,测试环境等变量应该受到严格控制。
行为指标例如:
任务完成时间
任务完成成功率
任务失败的次数
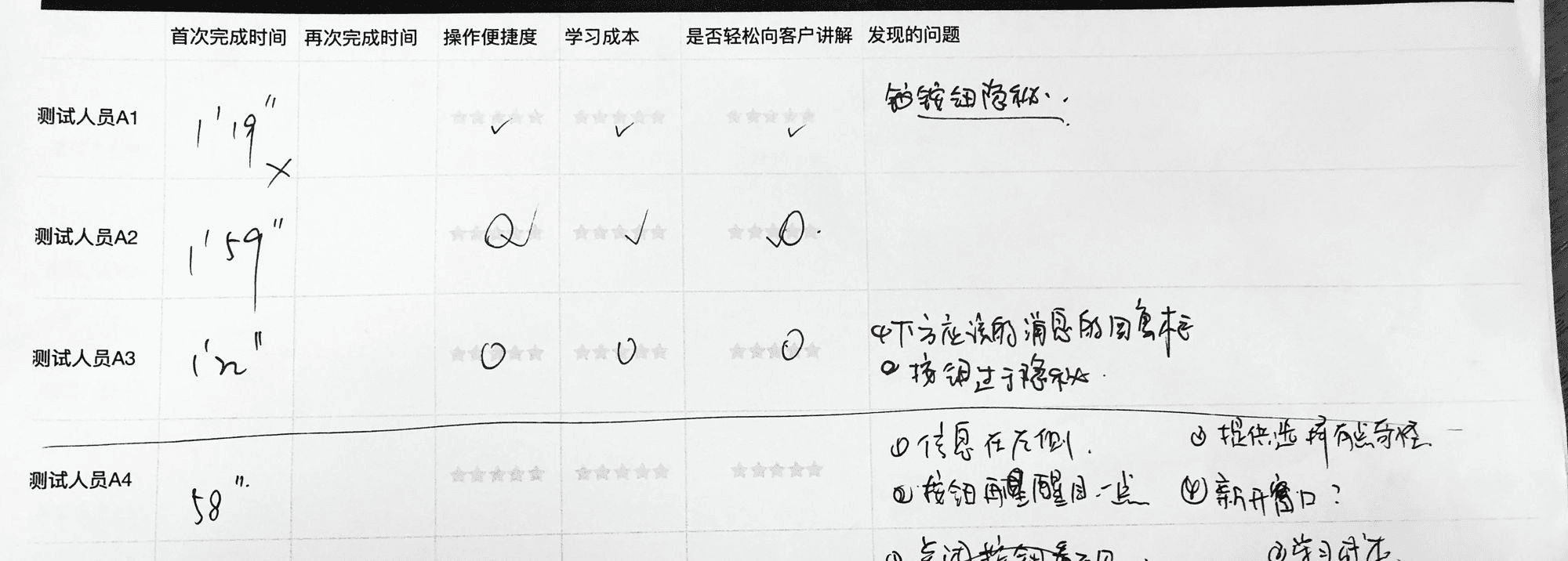
可用性指标例如:
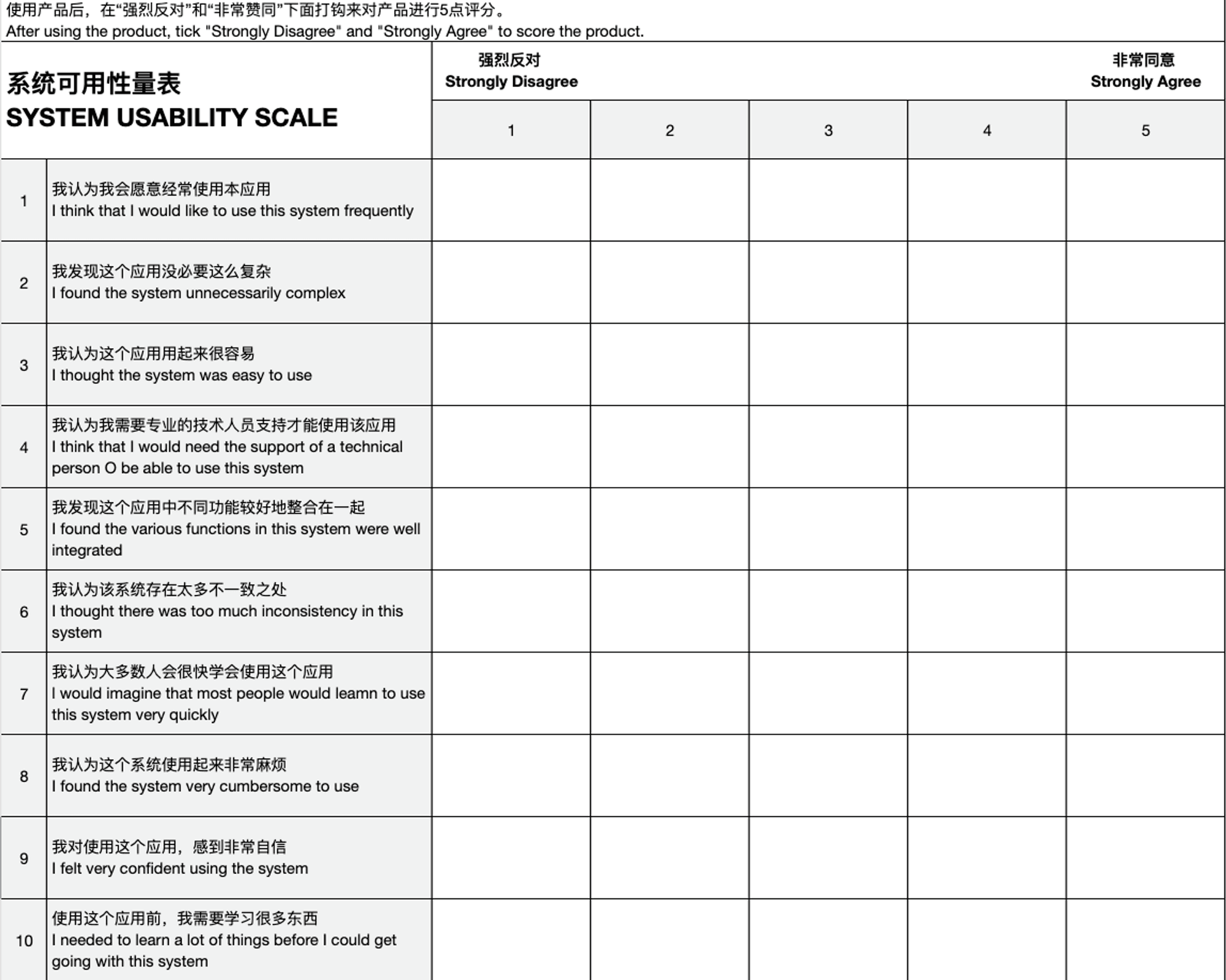
- SUS可用性量表
视觉也可以做量化的可用性测试,这通常需要借助眼动仪,指标如:
任务完成时间
首注视点达到的时间
首注视点时长
注视时长
注视点个数
定量的指标通常就是纯数字,如果没有参考,单一的定量指标就没有意义。举个例子,如果某个任务的平均完成成功率是60%,那么这说明设计是好的,还是坏的?恐怕很难从这个数字本身看出来——所以,此时需要一个已知标准、竞品数据、或者旧版设计来做参考。

在实际测试中少有纯量化的,或纯定性的可用性测试,一般研究人员会同时做一些定性的提问,来标记设计问题所在。或者在定性的测试之后,要求被试者填写一些量表(比如SUS量表),从而将两种数据进行结合。
定量的可用性测试数据的优点之一,在于能够计算出“显著性”。借助统计出的数据,我们可通过一些方法呈现出测试数据的可信程度和有效程度,置信区间和显著水平。使可用性测试的结果,更加掷地有声且客观。
- 统计显著性(statistical significance):运用概率来判断统计检验结果是否显著的一项指标。
四、其他有关测试的讨论
总的来说,可用性测试的操作过程并不复杂,但实施测试是有相当量的成本的。需要综合来衡量是否需要进行测试,以及进行到哪种程度。
4.1 测试的目的
从设计流程的角度上看,在进行“版本迭代”时,小型可用性测试即可发现并优化主要设计问题,此时的测试目的是为了形成设计稿,是“形成性”的。即通过定性的可用性测试来直接识别问题、优化设计,帮助“形成”更优的设计稿,甚至是在数个设计稿之间做抉择,速度更快,操作成本也更低。
在进行全方位的“设计评估”时,再去追求更精致的测试方案和测试报告,是“总结性”的,旨在提供对整个设计的完整评估。
从测试结果产出的角度上看,小型可用性测试可以发现当前设计稿存在的明显问题,设计师在分析后可以立即修复;更全面的可用性测试则注重长远目标,收集到的问题或优化建议很可能是未来某一个版本迭代的基础。
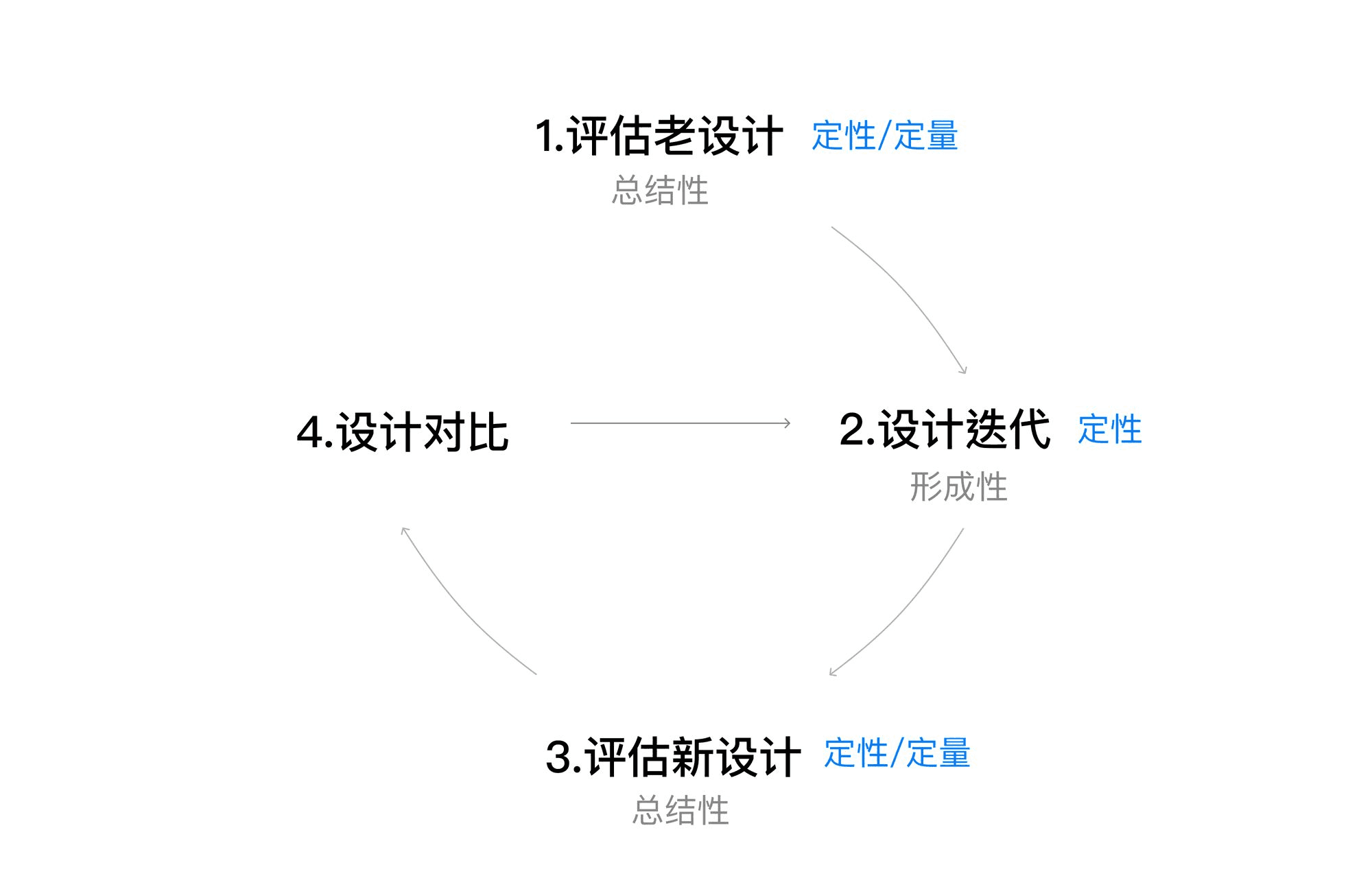
4.2 实施成本
最简单、低成本的可用性测试需要花3天,测试的地点可以选在会议室。当然,这前提是你已经提前联系好被试者了,或者你有现成的被试人员池。
Day 1:计划
Day 2:实施
Day 3:分析
但有时候,我们也需要规模更大的可用性测试,一些会额外增加成本的“可扩展测试项目” 例如:
多个平行的设计方案
跨时区测试
选择来自不同用户画像的被试
量化的测试项目
高级设备,比如眼动仪
高级环境,比如可用性实验室
对分析报告有更高要求
当测试的规模变大后,我们通常需要和用研、产品、运营、销售部门,甚至是跨国团队进行合作。同时,招募被试者时,所需提供的补贴也需要计入整体成本之中。
精致的测试方案可能性价比并不高。Jakob Nielsen 认为,对于定性的“形成性”可用性测试而言,5名被试者,就可以识别出85%的问题了,盲目追求更多被试将收效甚微。
参考文献
[1]吴遥.(2020).网页拟人化图标的注意加工机制及可用性测试 (硕士学位论文,浙江理工大学). [2]温郭英.(2017).可用性测试在web界面设计中的应用研究. 农家参谋 (16),294. [3]Kate Moran.(2019).Usability Testing 101.(www.nngroup.com/articles/usability-testing-101/) [4]Amy Schade.(2017).Write Better Qualitative Usability Tasks: Top 10 Mistakes to Avoid.(https://www.nngroup.com/articles/better-usability-tasks/) [5]Raluca Budiu.(2017).Quantitative vs. Qualitative Usability Testing.(https://www.nngroup.com/articles/quant-vs-qual/) [6]Jakob Nielsen.(2011).Parallel & Iterative Design + Competitive Testing = High Usability.(https://www.nngroup.com/articles/parallel-and-iterative-design/*)*


